Assemblies: locating, binding and deploying
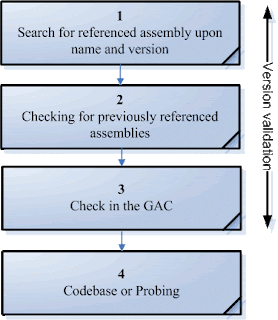
Introduction This article describes how the CLR locates and binds assemblies and how to change the default behavior when needed (e.g. in the deployment stage). Any developer and system administrator who deals with .NET assemblies, especially commercial applications, must be familiar with these topics. This knowledge is the best way to plan for service packs, upgrades and hot fixes as they come along. The .NET Framework is loaded (almost inflated) with a bunch of terms and features related to assembly deployment, locating and binding. Here is a short list: Static and dynamic loading Public and private GAC and private folder Probing Codebase BindingRedirect App.Config and Machine.config Strongly named and weakly named DevelopmentMode Audience The article is not at the beginner level, readers with basic knowledge in configuration files and assembly structure can also benefit from it right in the first reading. The quest for type resolving The CLR – Common Language...